Trademaxxing part6 : Lowering Order Ref Collisions (Hash : XOR Folding)
Introduction & Context
In the previous posts, we designed an entire custom ITCH parser, going all the way from raw ethernet parsing to having a market state.
The overall functional block diagram: 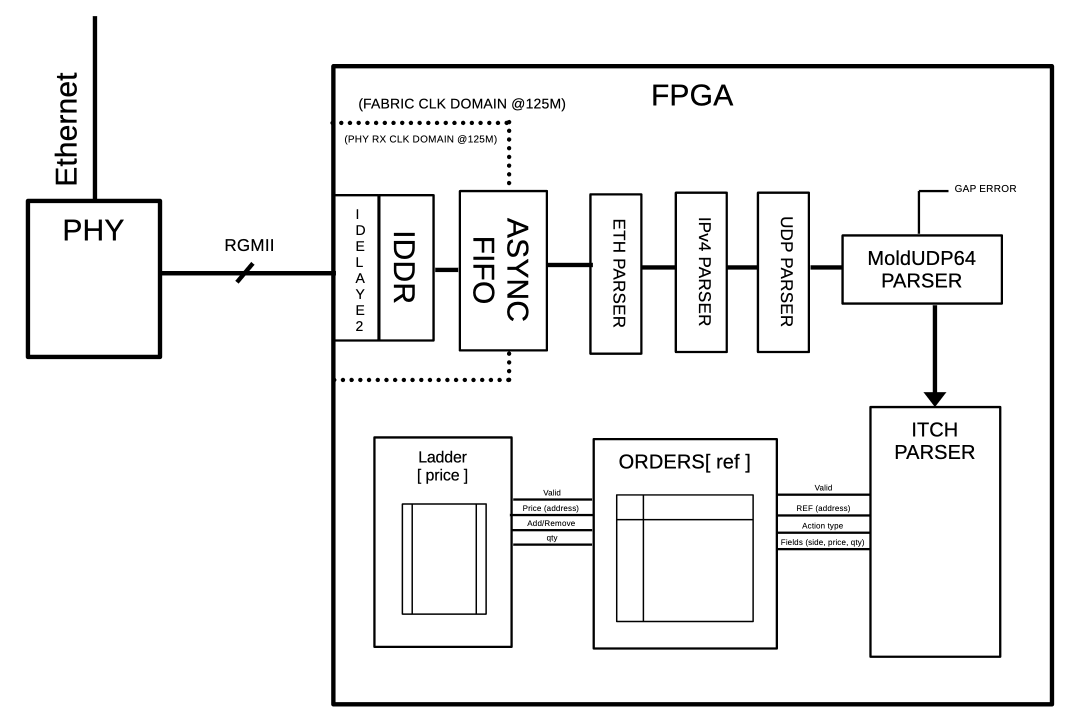
Focus on the order book: 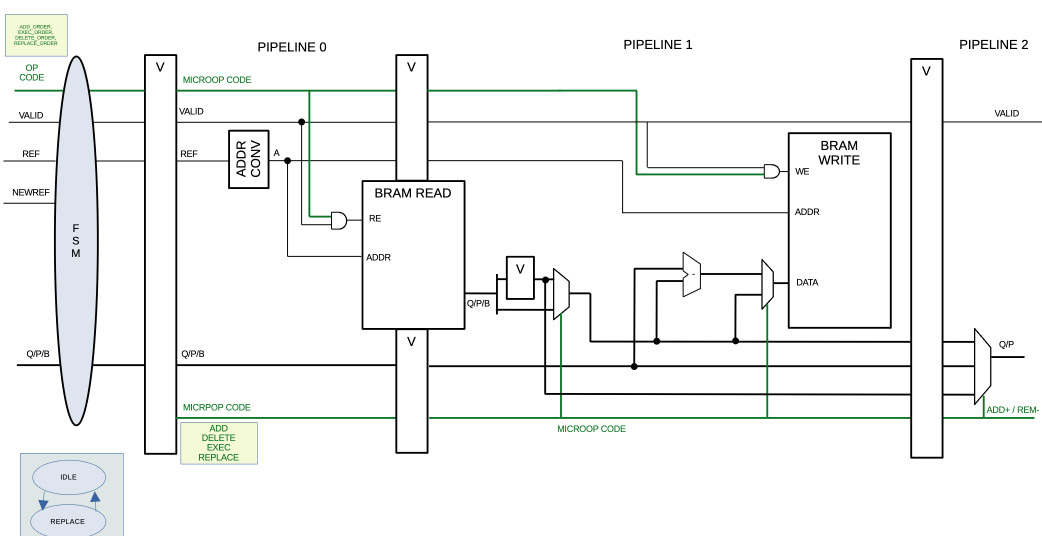
Focus on the ladder: 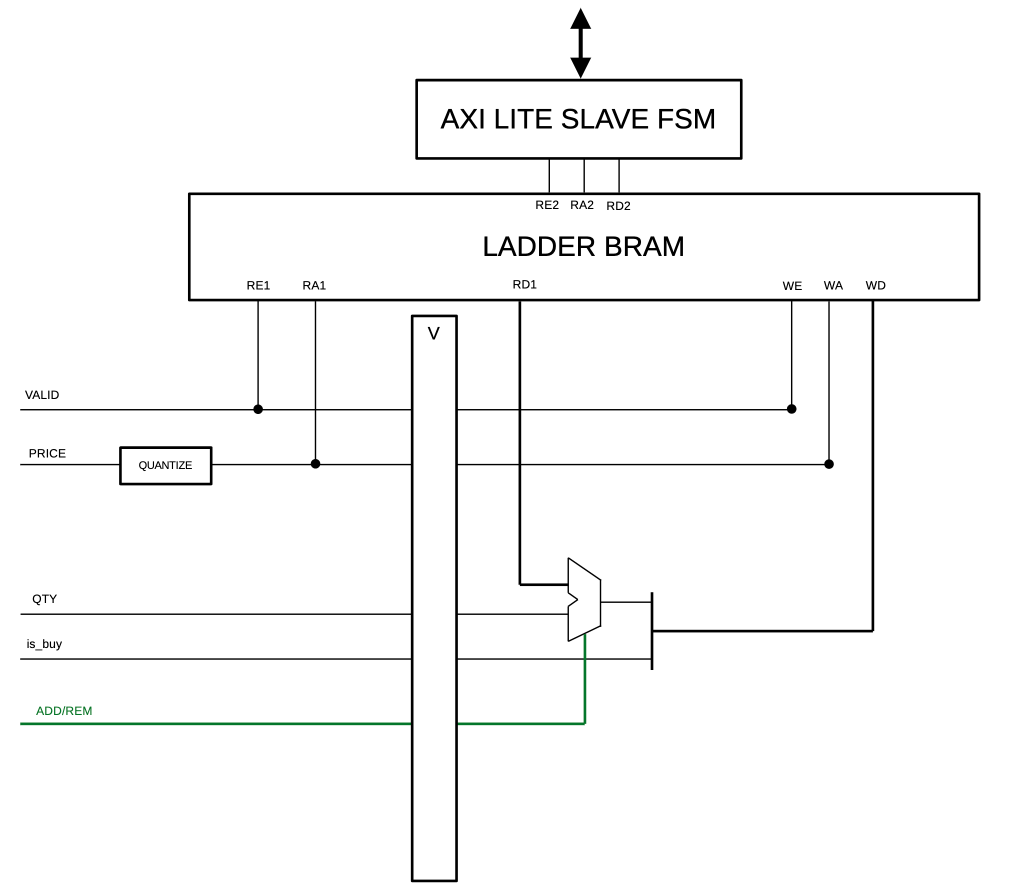
And as we saw in the previous post’s result analysis, we had some pretty promising results:
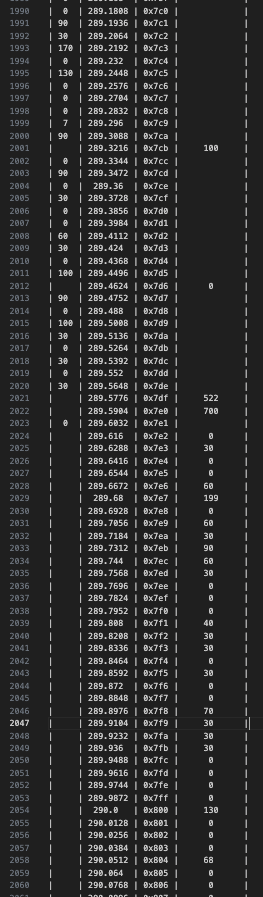
Absolutely everything is custom HDL (SystemVerilog), I’m not saying that to flex… Okay maybe a lil bit
But we also saw that there is an order crossing the spread (at addr 0x7CB) which is impossible, and after a bit of investigation, we saw that address collisions were causing state corruption in the order bookkeeper:
Focus on the order book: 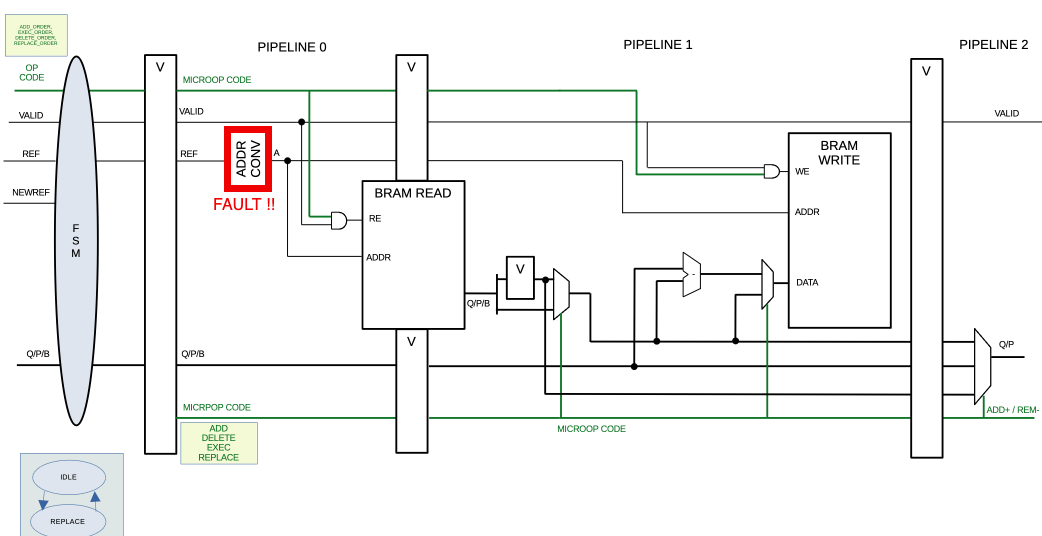
This address converter, whose job is to convert the 64-bit address ref into a 17-bit address that we can use to address a big BRAM, is necessary but does not really mitigate collisions. Why ?, well, take a look at the logic:
1
2
3
4
5
// addr_conv logic
// Addr conv (truncate)
logic [BRAM_ADDR_WIDTH-1:0] pipeline_0_addr;
assign pipeline_0_addr = pipeline_0_ref[BRAM_ADDR_WIDTH-1 + 4 : 4]; // some trick to minimize collisions, trust me, I'm a professional.
Yes, it simply takes a slice of the ref to use it as an address, which is not ideal. I did not want to make anything too complex back then to keep moving on with the design, I took a slice that I knew minimized collisions after a quick analysis on the ITCH binaries, but this solution is overdue, and today, we’ll explore how we can really mitigate, if not eliminate address collisions to avoid corruption.
Some Thoughts About the Problem
The problem has no perfect solution, collisions are mathematically impossible to avoid. But we know that a trading day can only have so many live orders on a single given market. And 2^17 should really cover most trading days.
Reminder: we only track 1 single stock, e.g. “
AAPL” or “ZYNE”.
For example, “AAPL”, which is a stock with very high volume, has 27308 PEAK live orders in the 12302019.NASDAQ_ITCH50 dataset analyzed. Given we have 100K+ entries available, this should be manageable, provided we map addresses properly and handle collisions.
Solution ?
Well this problem was already explored in the past (duh) and we have a pretty good first solution:
HASHING
Instead of taking a simple slice of the ref, we can hash it using various techniques, some more expensive than others hardware-wise, but this should drastically reduce the collision count.
Right now, in the analysis script running on 12302019.NASDAQ_ITCH50, our current “dumb solution” offers the following stats:
1
2
3
4
Peak simultaneous live orders : 27308
Final live orders : 219
Total collisions : 238418
Total unique refs seen : 795712
The low final live order count is normal as most positions are withdrawn before market close.
We see that we have a terrible collision rate (~29%), because the technique of using a slice worked on low-volume stocks (e.g. “ZYNE” with less than 1% collisions) but as volume increases, this solution falls apart. It’s just not reliable. A 1% collision rate would be acceptable for this demo, so that becomes the target.
So now, in the analysis script, we “simulate” an address translation through this function:
1
2
def addr_translate(ref: int) -> int:
return ref & 0x1FFFF << 4 # 17-bits BRAM address
Let’s replace it with this XOR folding method, which is not very hardware-intensive and (allegedly) delivers decent results:
1
2
3
4
def addr_translate(ref: int) -> int:
folded = (ref >> 32) ^ (ref & 0xFFFFFFFF) # fold top 32 into bottom 32
folded ^= folded >> 17 # mix within the 32b result
return folded & 0x1FFFF # grab 17 bits
And we get:
1
2
3
4
Peak simultaneous live orders : 27308
Final live orders : 219
Total collisions : 27474
Total unique refs seen : 795712
Which gets us down to a ~3% collision rate on one of the highest-volume stocks.
Impressive, very nice.
For reference, let’s run this on “ZYNE”, a low-volume stock:
Before (bitslice addr [18:2]):
1
2
3
4
Peak simultaneous live orders : 921
Final live orders : 3
Total collisions : 67
Total unique refs seen : 12769
(~0.5% collision rate)
After (XOR folding):
1
2
3
4
Peak simultaneous live orders : 921
Final live orders : 3
Total collisions : 95
Total unique refs seen : 12769
(~0.7% collision rate)
So while it’s not strictly better in all cases, XOR folding scales much better for higher volumes, which is what matters here.
Testing XOR Folding
For now, let’s forget about collision handling and test this XOR folding method to see where it takes us.
We implement it in the HDL and run the overall simulation, tracking “AAPL” stocks, and we observe the price ladder:
Now that’s a far more cohesive spread. Note there are 50,000 messages taken into account here so:
- The spread absolute price moved from the previous demo, which is normal as we are further into the trading day (10x more in fact…).
- There is still an order crossing the spread.
But, given 50k “AAPL” messages are taken into account here, the state is still pretty coherent, whereas the old bitslice technique may have produced completely corrupted results, as errors accumulate over time.
Future Work ?
3% collision rate? Acceptable for a demo. BUT real collision handling is still on the agenda.
This project is more of a portfolio project, and maybe a demo for a video. This is not intended for real trading.
Proper collision handling would require detecting conflicts, possibly remapping entries, adding translation tables, and likely consuming more BRAM… which is intentionally avoided here.
For now, the next step is to move to a real FPGA demo.
Thank you for reading to this point. You can write a comment below if you have any questions.
Godspeed
-BRH