Trademaxxing part1 : Parsing MoldUDP64
Introduction
I’d say I’m a normal guy, but I’ve always liked very stupid projects.
You may not know it but I have a decent interest in finance. So today we are exploring how FPGAs are used to process market data in order to make decisions as fast as possible.
This will in turn allow us to implement shitty financial strats as HDL without any overhead, allowing us to dilapidate our money at lightning speeds and become poor ASAP.
WHY FPGAs ?
CPUs are stupid and full of BLOAT.
Unless you are using a baremetal program on the HOLY CORE (the best CPU ever), your delays are awful and undeterministic, making C++ developers and their fancy 1ms execution times cry as they see literal logic gates crush their useless and bloated perfs, which could have been made better by claude.ai anyway. GG for them.
Us hardware devs still have a couple of years to go before AI replaces us, this leaves us some time to mock software devs before we get replaced too, so let me enjoy it while it lasts
Anyway, when you wanna capture a spread and/or execute arbitrage strategies, the first to pass orders is the one who wins. These strategies are often dumb simple and to get the bags, it doesn’t come down to who has the best quant but rather who can buy/sell the fastest as the opportunities are only present for milliseconds.
This is why FPGAs are appreciated. The time it takes to RX an ethernet packet and TX an order can be very small, like under 100ns but that’s the whole point, you have to be first and no matter if it’s 1-2 nanoseconds before the guy next door, if you are first it’s GG and you get the bags.
MoldUDP64
Okay so in this post, we’ll try to figure out how to parse incoming ethernet frames. We won’t process any data yet nor keep track of the market state. No. The objective here is simply to understand how one can get market data, what it is and how to parse the incoming data to get to the PAYLOAD i.e. market data.
MoldUDP64 & ITCH.. What are those ?
ITCH is the Nasdaq protocol where they’ll broadcast market events. It’s received in FPGAs via ethernet and the frames follow the MoldUDP standard that looks like this:
1
Ethernet Frame -> IPv4 headers -> UDP Headers -> MoldUDP64 -> ITCH Messages
Or even better with an image:

I won’t get into the specifics of IPv4 and UDP.
MoldUDP64 is simple and only contains a few fields:
| Field Name | Length | Value | Notes |
|---|---|---|---|
| Session | 0 | 10 | Session ID, don’t care much |
| Sequence Number | 10 | 8 | First message’s sequence number. 1 per message. Can use that and compare with last seq message and check if we missed something. Each message has one so if we get seq = 10 and message count = 5 then the next frame should have number 16 as seq number. |
| Message Count | 18 | 2 | The number of messages in the packet |
Our goal here will be to filter incoming packets, we only want:
- IPv4 UDP packets
- That contain MoldUDP64
So it’s mostly just a big forwarding funnel / pipeline (whatever you wanna call it).
The only thing “out of the ordinary” this pipeline can and will do is detect missing packets using the Sequence Number field, which contains the first message’s number.
E.g. if you miss a frame and seq number does not match the previous message you handled… it means you missed some orders.
Now Nasdaq being very smart gives you another server you can request missing packets from. Which we won’t do in the context of our demo, instead, when a missing packet is detected, we raise a sequential packet_gap_error we can later use as a reset signal or an interrupt if I decide to add a monitoring CPU to the system.
Anyway, that’s the idea of what we need to do to access the ITCH messages, again, we don’t wanna process them yet.
FPGA design
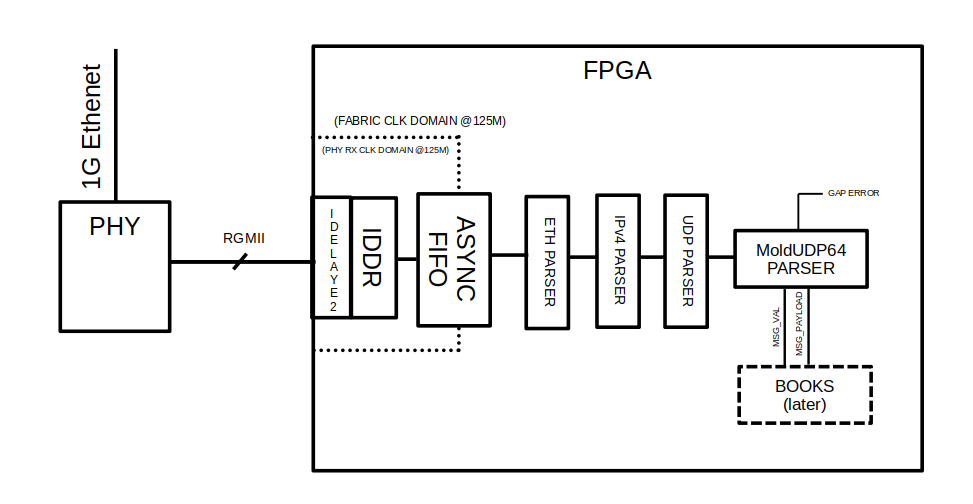
AXI stream is used as a standard connection between parsers.
So the design is pretty straightforward. Because this project is more of a demo, the ethernet speed is limited to 1Gbps as I plan on using a KC705 board:

Each parser revolves around a simple FSM and a byte counter, then looks at the upcoming data, parses the respective fields by transitioning states.
If a frame is not valid (has to be filtered out), it simply goes back to IDLE and waits for the data stream to end by monitoring the AXIS’ tlast.
If a frame passes the couple of checks, the parser transitions into FORWARDING state and will open the gate to the next parser, but it only passes its payload meaning the “bloat” headers are dropped at each step.
Here is an example, the simplest (UDP parsing) where we literally have no filter implemented:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
// udp_parser.sv
/* UDP Parser
*
* This parser is pretty much just a forwarder that cuts out the UDP headers
* As the UDP port, just like some IPv4 params, depend on the day-to-day instructions from Nasdaq,
* We'll just forward stuff for the most part, very simple design.
*
* BRH 03/2026
*/
module udp_parser (
input logic clk,
input logic rst_n,
AXI_STREAM_BUS.Rx axis_in,
AXI_STREAM_BUS.Tx axis_out
);
// these states represent
typedef enum logic [3:0] {
IDLE,
SRC_PORT,
DST_PORT,
LENGTH,
HEADER_CHECKSUM,
FORWARDING
} state_t;
state_t state, next_state;
// we track ongoing frame
logic ongoing_frame;
// Global bytes counter
logic [7:0] bytes_counter;
always_ff @(posedge clk) begin
if(~rst_n) begin
state <= IDLE;
ongoing_frame <= 0;
bytes_counter <= 0;
end else begin
state <= next_state;
// track ongoing frame
ongoing_frame <= ongoing_frame;
if(axis_in.tlast) begin
ongoing_frame <= 0;
end else if(state == IDLE && axis_in.tvalid) begin
ongoing_frame <= 1;
end
// update byte counter
if(axis_in.tvalid && (state != IDLE)) begin
bytes_counter <= axis_in.tlast ? 0 : bytes_counter + 1;
end else begin
bytes_counter <= bytes_counter;
end
end
end
always_comb begin
// default assignments
next_state = state;
axis_out.tvalid = 0;
axis_out.tdata = 0;
axis_out.tlast = 0;
axis_in.tready = 1;
case (state)
IDLE : begin
if(axis_in.tvalid && ~ongoing_frame) next_state = SRC_PORT;
axis_in.tready = 0;
end
SRC_PORT : begin
if(bytes_counter == 1 && axis_in.tvalid) next_state = DST_PORT;
end
DST_PORT : begin
if(bytes_counter == 3 && axis_in.tvalid) next_state = LENGTH;
end
LENGTH : begin
if(bytes_counter == 5 && axis_in.tvalid) next_state = HEADER_CHECKSUM;
end
HEADER_CHECKSUM : begin
if(bytes_counter == 7 && axis_in.tvalid) next_state = FORWARDING;
end
FORWARDING : begin
// as long as TLAST does not hit, marking the end of the ethernet payload
// (RX parser only gives us the raw payload, nothing else)
// we keep on forwarding the selected data to next parser
axis_out.tvalid = axis_in.tvalid;
axis_out.tdata = axis_in.tdata;
axis_in.tready = axis_out.tready;
axis_out.tlast = axis_in.tlast;
end
default: ;
endcase
if(axis_in.tlast && axis_in.tvalid) next_state = IDLE;
end
endmodule
In fact, the checks are kept minimal for the demo, lust like what most of my parsers do: they just count bytes until they can start forwarding, effectively just stripping the bloated protocol header.
Verification
In summary, the design is very simple and it’s just a matter of stripping off headers from a stream, nothing fancy.
You can see this simplicity really translate in simulation where we just see streams getting progressively stripped of their headers.
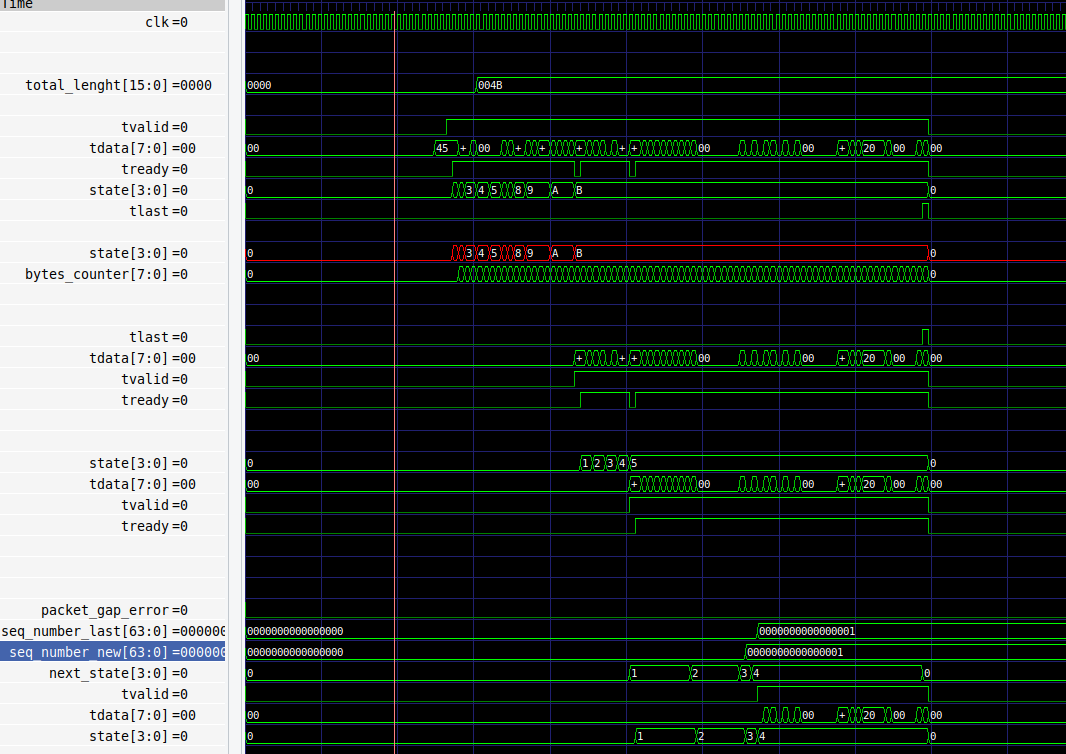
This simulation is based on a cocotb/verilator testbench. The RGMII signals are known to be valid & standard because I used the cocotbext-eth extension.
The frame data itself is a fake fixed example that contains a single ITCH R message at the end. It serves as a template to design the initial parsers, I asked claude to generate it from the various IPv4/UDP/MoldUDP64 specs:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
# test_trademaxxer.py
# ...
@cocotb.test()
async def test_tardemaxxer_basic(dut):
# ...
rgmii_source = RgmiiSource(dut.rgmii_rxd, dut.rgmii_rx_ctl, dut.rgmii_rxc, dut.rst)
raw_data = bytes([
# -------------------------
# Ethernet Header (14B)
# -------------------------
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, # dst MAC (broadcast)
0xDE, 0xAD, 0xBE, 0xEF, 0x00, 0x01, # src MAC
0x08, 0x00, # ethertype IPv4
# -------------------------
# IP Header (20B)
# -------------------------
0x45, # version=4, IHL=5 (20B, no options)
0x00, # DSCP/ECN
0x00, 0x4B, # total length = 75B (20 IP + 8 UDP + 20 MoldUDP64 + 2 msg len + 25 ITCH R)
0x00, 0x00, # identification
0x00, 0x00, # flags + fragment offset
0x40, # TTL = 64
0x11, # protocol = UDP
0x00, 0x00, # checksum (0 = disabled)
0xC0, 0xA8, 0x01, 0x01, # src IP 192.168.1.1
0xE9, 0x36, 0x0C, 0x6F, # dst IP 233.54.12.111 (multicast)
# -------------------------
# UDP Header (8B)
# -------------------------
0x30, 0x39, # src port 12345
0x67, 0x48, # dst port 26456 (ITCH)
0x00, 0x37, # length = 55B (8 UDP + 20 MoldUDP64 + 2 msg len + 25 ITCH R)
0x00, 0x00, # checksum disabled
# -------------------------
# MoldUDP64 Header (20B)
# -------------------------
0x53, 0x32, 0x30, 0x31, 0x39, 0x30, 0x31, 0x33, 0x30, 0x20, # session "S20190130 "
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, # sequence number = 1
0x00, 0x01, # message count = 1
# -------------------------
# MoldUDP64 message envelope
# -------------------------
0x00, 0x19, # message length = 25B (ITCH Stock Directory R)
# -------------------------
# ITCH Stock Directory (type R) - 25B
# -------------------------
0x52, # message type 'R'
0x00, 0x2A, # stock locate = 42 (AAPL = 42 today)
0x00, 0x01, # tracking number (bloat)
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, # timestamp (nanoseconds since midnight)
0x41, 0x41, 0x50, 0x4C, 0x20, 0x20, 0x20, 0x20, # symbol "AAPL " (8B space padded)
0x4E, # market category 'N' (Nasdaq)
0x00, # financial status indicator
0x00, 0x00, 0x00, 0x01, # round lot size = 1
0x4E, # round lots only 'N'
])
await rgmii_source.send(GmiiFrame.from_payload(raw_data))
# ...
In the future, we’ll use real Nasdaq data as they give binary outputs that we can use for this purpose.
Upcoming Work
Now we have to design an ITCH bookkeeper, that will decode the nature of the incoming messages and act upon an order list + “price ladder”. The goal will be to only cover a single stock like AAPL to keep things simple as that is just a demo.
But that… is for another post !
Thank you for reading to this point. You can write a comment below if you have any questions.
Godspeed
-BRH